![]() After several years of research and development BroadBit proudly presents its AI (Artificial Intelligence) based application, named AutoMeta, to its customers and partners. This application, with its continuous learning capability, can extract useful data from unstructured content – with minimal human interaction.
After several years of research and development BroadBit proudly presents its AI (Artificial Intelligence) based application, named AutoMeta, to its customers and partners. This application, with its continuous learning capability, can extract useful data from unstructured content – with minimal human interaction.
Automated Document Metadata Extraction
AutoMeta AI first detects the language and the type of the document. Then, using these parameters, it is able to automatically extract type-relevant metadata with high accuracy.
Our new product is using AutoMeta too, see: collAIgue.com
For example: from a digitized invoice, certificate of fulfillment, or a work-related document, we are able to extract the following metadata: ID, account numbers, partner data, total payment due, project, year of birth etc.
The main purpose of AutoMeta is to retrieve file contents from document management systems (Alfresco, SharePoint, FileNet, etc.), databases (MS SQL Server, PostgreSQL, Oracle, etc.) or file systems. From these files, it collects key-value pairs. The processed documents can then be uploaded to a target system (defined by “endpoints”), which can be different from the source system.
AutoMeta is able to operate as a „Repository Crawler„. With its internal scheduler, it can connect to a DMS server periodically, downloading documents that need to be processed, and then automatically extending the document metadata with the extracted results.
A single AutoMeta instance supports multiple DMS, database and file system connections. Depending on its configuration, it can extract data from documents, or perform transformations on them. During a transformation, data can be migrated between systems, for example, when processing documents from a file system, it can upload the documents (with extracted metadata) to a DMS/CMIS repository (e.g. Alfresco, SharePoint).
A classical use-case is given as follows. Let us assume that a customer has a shared, network filesystem or a DVD, containing its archive documents. The customer aims to move these documents to a DMS. During a migration or replication (from shared network filesystem, DVD etc.) to DMS, AutoMeta is also processing the documents. The result of the migration is a collection of searchable documents, where both content and metadata are indexed.
AutoMeta consists of several machine learning based software components. Some of them require human interaction for learning, meanwhile others use self-learning techniques to improve accuracy. The learning process can be language- and document type dependent, although global patterns are also available. This can be tailored to the needs of potential partners and projects.
AutoMeta relies on content transformation (OCR, Binary to Text, Barcode, Computer Vision, Image to PDF, etc.), static templates and machine learning features (e.g. classification, page structure and color detection, etc.) for its data extraction. This combination of the previously mentioned features enables autonomous operation.
AutoMeta features:
-
- On-premise and/or cloud based operation (on/premise mode ensures the sensitive data do no leave the enterprise)
- Scalable, multi-platform technology (Java Virtual Machine)
- Multi-language AI module (European and Asian languages are supported by AutoMeta)
- Process Monitoring Interface
- Multi-language classification frontend (to support AI learning), cooperative work support with circular inspection.
- The pre-classification is performed by AutoMeta AI. However this pre-classification should be approved by a human operator. Therefore, the pre-classification contains “two steps”, where the first initial key-values are presented by AutoMeta on its user interface. In the second phase the suggested key-value pairs should be approved or rejected by the customer.
- Processing and converting images (JPEG, TIFF, …), Office (LibreOffice, MS Office files) and PDF documents.
- Creating Multi-layer (image and searchable text) PDFs, with built-in OCR
- The optical character recognition algorithm can be supported with dedicated GPU, therefore it supports parallel document process.
- Voice recognition in audio files (MP3, OGG, …) and process text
- Digital sign of PDF documents (cooperate level)
- Check digital signature of PDF documents
- Barcode, QR code recognition and creation (to the document image)
- Machine Readable Zone (MRZ), TD1. TD2, TD3, MRV-A, MRV-B value extraction (passports, id cards, etc.)
- Applying CMIS repositories as data source and target.
- Complex filesystem and folder structure as data source and target.
- Database systems (SQL) as data source and target.
- Time triggered operation (in this case AutoMeta calls the data source- and target systems during its process)
- Service based operation (AutoMeta applies SOAP and REST interfaces to connect to data source system).
- Key-value pair extraction from unstructured data (e.g. “documentId=ABCD-E/2019”, “dateOfCompliance=2016.08.08”))
- extraction of fix fields (e.g. in SAP integration the metadata should be included to XML tags)
- extraction of dynamic fields
- Detecting document language and type.
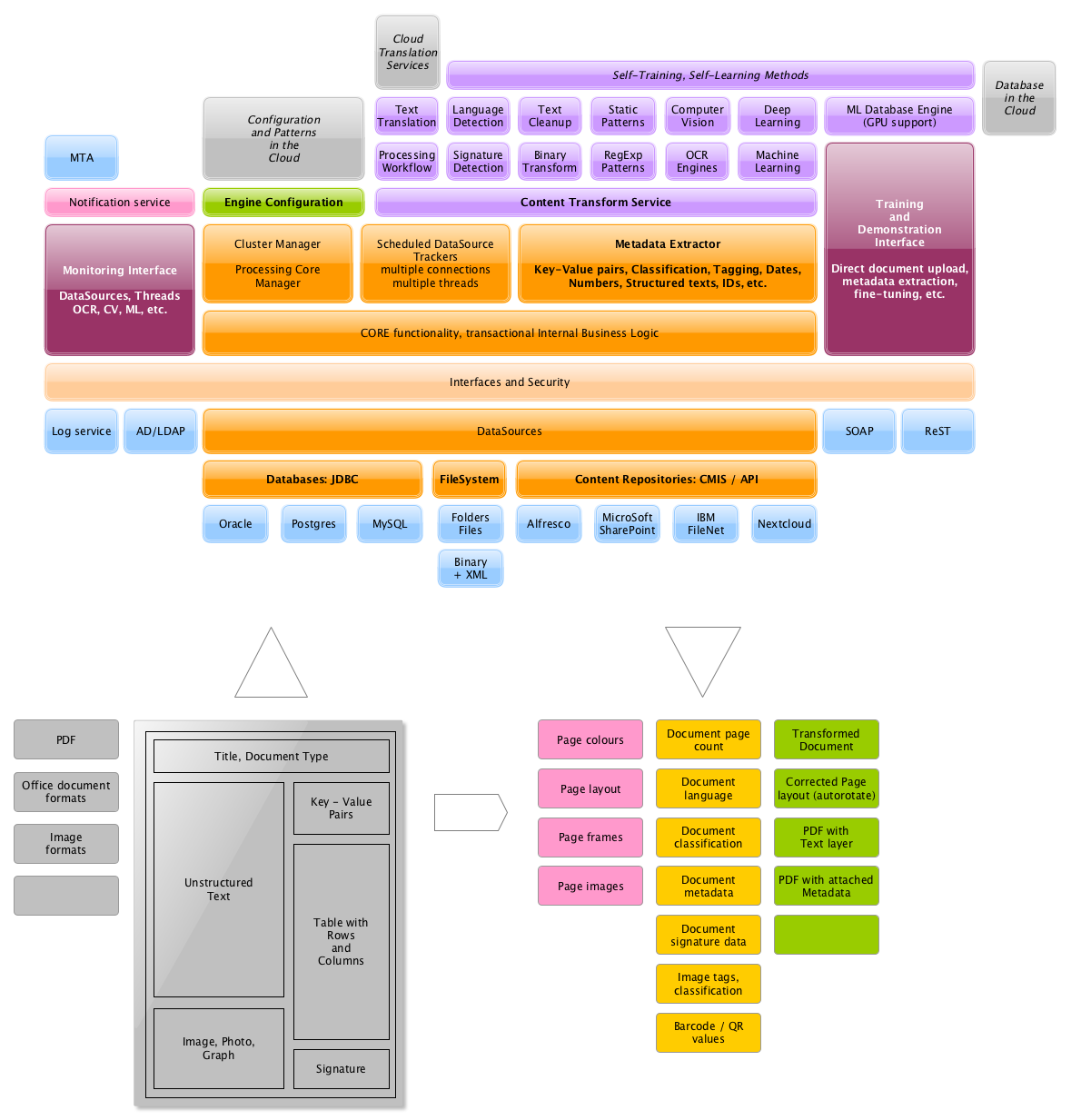
AutoMeta components:
Shown here are the components of the AutoMeta system, its layers, the data source, and the structured data extracted.
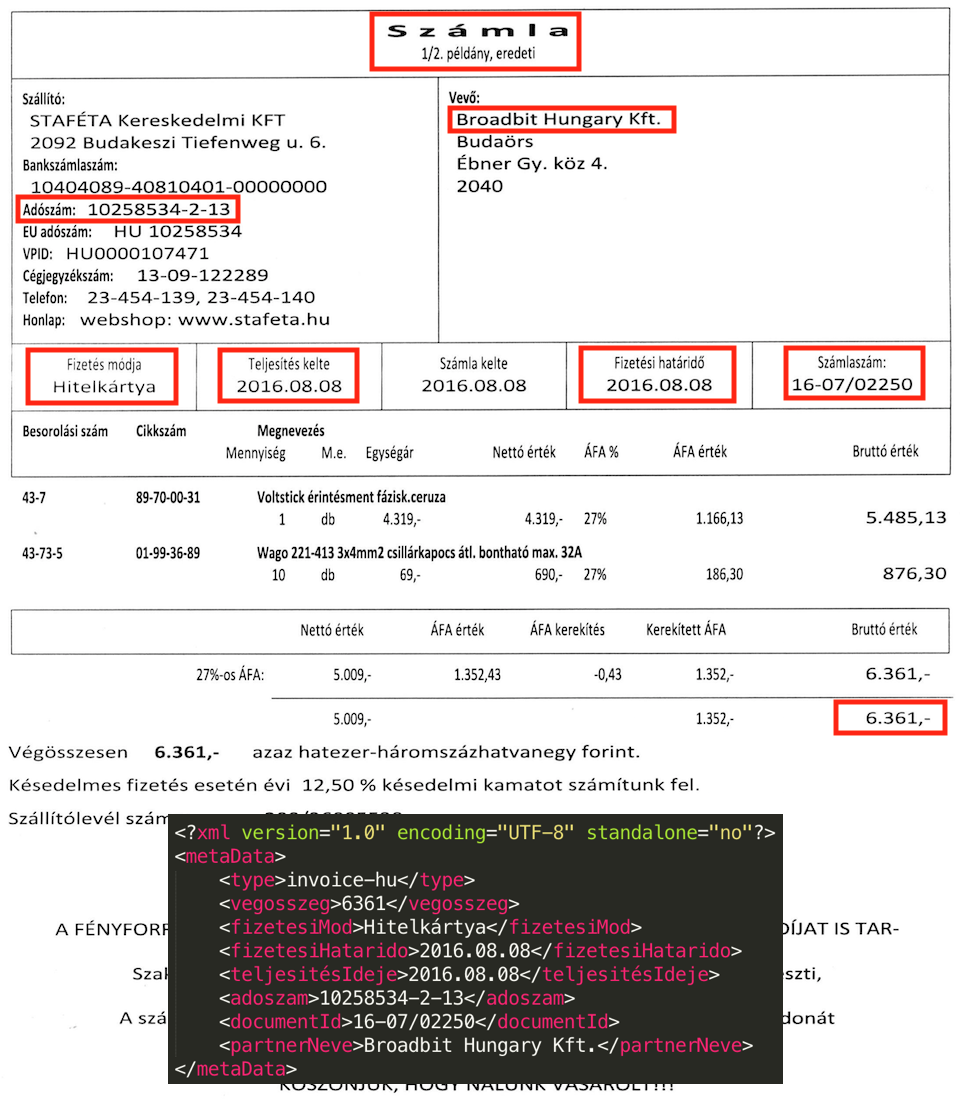
Data extract samples:
In the following we present the processed documents and the key-value pair results produced by AutoMeta. The images show that the same metadata set needs to be extracted from different structures. OCR errors can further complicate this process.
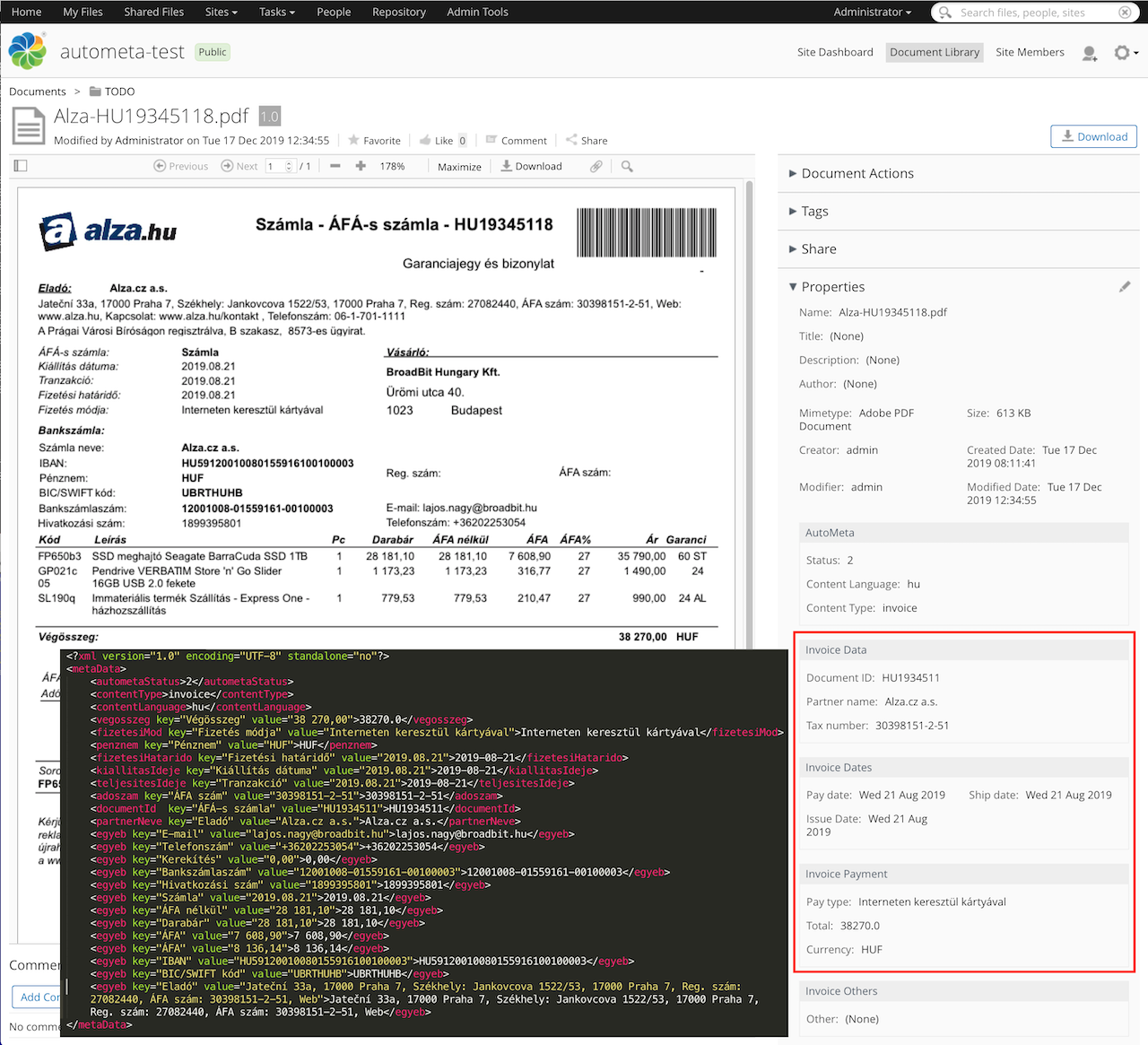
Alfresco ECM – AutoMeta integration
The metadata extracted from a document are stored in properties defined in the document model of the Alfresco Content Service. In the XML structure shown below, in addition to important fixed fields (stored in Alfresco as metadata), dynamic key-value fields can be seen, represented in a manner similar to Amazon Textract.
Alfresco ECM participates in the integration as a server. AutoMeta connects to this server via CMIS protocol. In Alfresco, the documents that need to processed by AutoMeta are marked with a dedicated metadata value (“AutoMeta:status=0”).
AutoMeta collects the documents with a CMIS search query. Processing can run on multiple threads. After successful AutoMeta processing, documents (binaries and the extracted metadata) are uploaded to Alfresco as new versions.
During our testing, a scanner (with WebDAV protocol support) is connected to Alfresco. AutoMeta executes the OCR process on the scanned document (providing a searchable text layer on the PDF) and extracts the metadata that are relevant to the given document type. At the end of the process, the original scanned PDF is replaced with a PDF with metadata, where both content and metadata are indexed, and therefore searchable in Alfresco.