Alfresco ECM – AutoMeta integráció
A dokumentumkezelés automatizálásának egyik fő állomása az iratok gépi rendszerezése, metaadatokkal való ellátása, illetve a metaadatok alapján való szortírozása. Az alkalmazott DMS-ek nagy részénél ez manuálisan történik, azaz E-Mail-ben csatolmányként, vagy Szkennerből képként érkező iratot az Iratkezelésen dolgozók látnak el metaadatokkal.
El kell választani egymástól a szinte tökéletes biztonsággal kinyerhető adatokat (pl.: vonalkód, QR kód) a gép számára strukturálatlan adatoktól. A strukturálatlan adatokat – gondoljunk csak a számlák kötetlen formáira, kevert nyelveire, színekkel és logókkal tarkított megjelenésére és a sokszor fölöslegesen használt kulcsszó-rövidítéseire – csak megfelelően betanított mesterséges intelligencia (AI) alkalmazásával lehet felismerni.
Az AI tanítása nagyon hasonlít egy új munkatárs betanításához, megmutatjuk neki az irattípusokat és megtanítjuk, hogy az iratképen mely adatok fontosak, mihez kapcsolódnak és hogy kell értelmezni az értékeket. Megfelelő mennyiségű training után már magától el fogja véhezni a feladatot – nekünk viszont ellenőriznünk kell és be is kell avatkoznunk abban az esetben, ha valamiért rosszul dolgozik.
Az Alfresco – AutoMeta integrációval az a célunk, hogy a dokumentumkezelő rendszereknél a manuális adatrögzítést jelentősen megkönnyítsük. Megfelelő integráció és tanítás után az iratkezeléssel foglalkozó munkatársak manuális tevékenysége az AutoMeta által kinyert adatok ellenőrzésére és jóváhagyására korlátozódik.
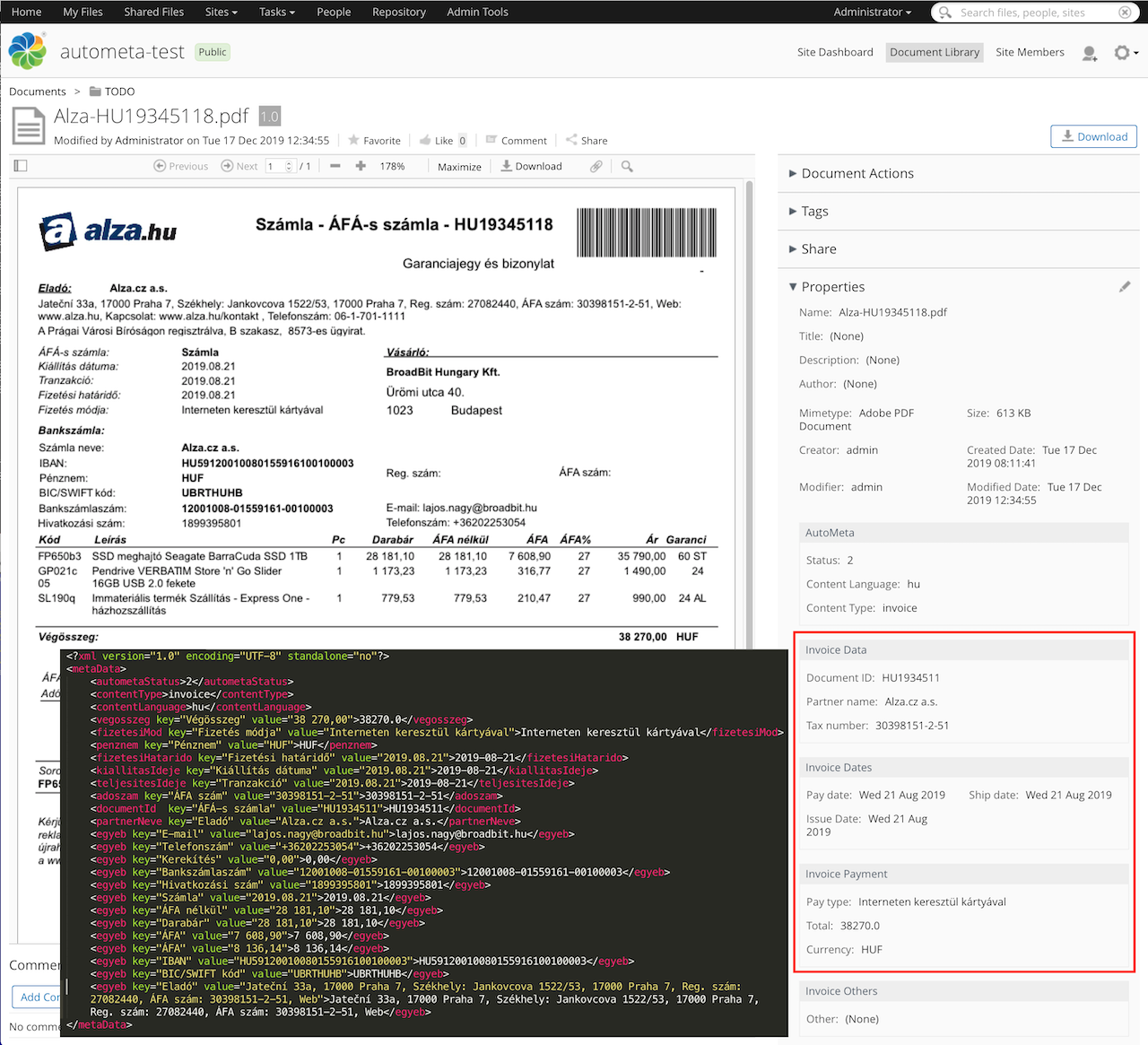
Az Alfresco Content Service-ben létrehozott dokumentum-modell metaadataiban kerülnek letárolásra a dokumentumból kinyert értékek. A lenti képen megjelenő XML struktúrában látszik, hogy a kiemelt és metaadatban letárolt értékek (fix mezők) mellett az Amazon Textract-hoz hasonló kulcs-érték páros adatok (dinamikus mezők) is megjelennek (lásd: „egyéb”).
Az integrációban az Alfresco ECM mint szerver vesz részt, az AutoMeta CMIS protokollon keresztül csatlakozik hozzá. Az Alfresco repository-ban egy dedikált metaadattal („AutoMeta:status=0”) megjelölésre kerülnek a feldolgozandó dokumentumok, melyeket CMIS query-vel kér el az AutoMeta. A feldolgozás több szálon történik, az AutoMeta műveletek végeztével a metaadatok és dokumentum binárisa is visszatöltésre kerül az Alfresco-ba, mint új dokumentum verzió.
Az implementáció során egy Alfresco-val CIFS, vagy WebDAV protokollon összekötött szkennerből érkezik a dokumentum, melyen egy metaadattal megjelöljük, hogy feldolgozandó.
Az AutoMeta CMIS protokollon csatlakozik az Alfresco-hoz, lekéri a feldolgozandó dokumentumot, OCR-ezi (ellátja kereshető szöveges réteggel).
Az AutoMeta meghatározza az irat elsődleges nyelvét és típusát, majd kinyeri belőle a dokumentumtípusra jellemző és definiált metaadatokat.
A folyamat végén a szkennelt PDF helyére egy indexelt, metaadatokra és beltartalomra is kereshető dokumentum kerül vissza az Alfresco repository-ba.