AutoMeta AI – dobozolás folyamatban!
Nagy élmény, mikor egy végeláthatatlannak tűnő, mérnőkórák ezreit felemésztő fejlesztés végre beérik, a számtalan apró komponens végre összeáll, és megmozdul a mesterséges értelem! Az első közös teszteken még félve figyeltük, hogy mit művel, de nem kellett csalódnunk, teszi a dolgát, gyorsan és pontosan, ahogy szerettük volna és ahogy majd folyamatosan tanítgatva is elvárjuk azt tőle.
Azt hiszem, kijár egy virtuális óriásplakát, graffitiművészkedéssel és egy szép nagy gratuláció a csapatnak érte!

![]() Több éves belső kutatás-fejlesztés után hamarosan az ügyfeleink és partnereink számára is elérhetővé tesszük a BroadBit saját fejlesztésű AI (Mesterséges Intelligencia) eszközét az AutoMeta-t, mely folyamatosan tanulva – minimális emberi beavatkozással – képes strukturálatlan adatokból értékes adatokat előállítani.
Több éves belső kutatás-fejlesztés után hamarosan az ügyfeleink és partnereink számára is elérhetővé tesszük a BroadBit saját fejlesztésű AI (Mesterséges Intelligencia) eszközét az AutoMeta-t, mely folyamatosan tanulva – minimális emberi beavatkozással – képes strukturálatlan adatokból értékes adatokat előállítani.
Mivel elsődlegesen dokumentumkezeléssel foglalkozunk és látjuk a jó minőségű dokumentumtárakhoz szükséges metaadatok előállításának költségeit, igyekeztünk automatizálni ezeket a műveleteket – az előzetes eredményeink alapján nyugodtan megbízhatunk a gépi munkatársban…
Az AutoMeta AI felismeri az iratok nyelvét és az irattípusokat, majd a típusoknak megfelelően képes a típusra jellemző adatokat nagy pontossággal, automatikusan kinyerni. Legyen szó digitalizált számlákról, teljesítés-igazolásokról, vagy munkaügyi iratokról – meg tudjuk határozni az irathoz szorosan kapcsolódó adatokat, úgymint: Számlaszám, Teljesítés ideje, Partner, Végösszeg, Projekt, Születési év, stb.
További információk: AutoMeta AI
Egy demóhoz készült konfigurációban megtanítottunk az AutoMeta-nak magyar nyelvű számlákat, majd ráengedtük az AI-t a tanításban résztvevő, illetve számára ismeretlen dokumentumokra is – az eredmény nagyon-nagyon biztató, ha a szkennelés minősége megfelelő, akkor mindkét esetben ragyogó eredményeket kapunk (néhány minta)!
A lenti képen az látható, hogy sikerült pontosan meghatározni a dokumentum típusát és nyelvét (“invoice-hu”), majd az endpoint-konfigurációban megadott kulcsokhoz (lásd a magyar nyelvű XML tag-eket) kellett találnia értékeket.
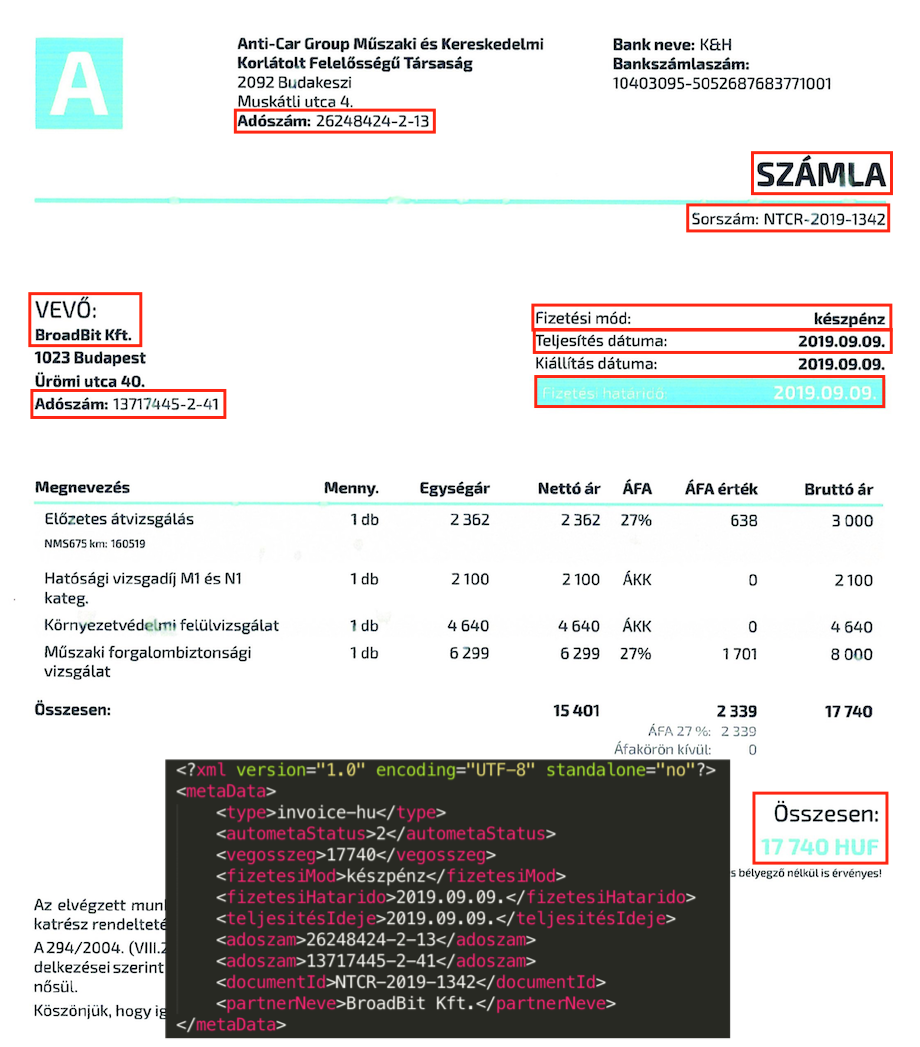
A magyar nyelvű számlák csak az első lépés, most következik egy nemzetközi projektben az integráció (SAP + Alfresco + AutoMeta), illetve az olyan szépségek, mint a kevert nyelvek, a cirill betűs iratok, kínai és arab írásmódok – mindezek üzleti dokumentumok esetén.
Így csöndesen idebiggyesztjük a végére, hogy magyar nyelvű iratok esetén sikerült az Amazon Textract-nál jobb eredményeket elérnünk – és ezek az eredmények még javulni fognak, remélhetőleg sokáig. Volt a csapatban olyan, aki ledobta a láncot, mikor elkezdtünk azon gondolkozni, hogy miként fogjuk az AutoMeta AI-t egy másik AutoMeta AI-jal tanítani kulcs-érték párok klasszifikációjára… 🙂