AutoMeta – Dokumentumfeldolgozási és transzformációs keretrendszer
Az enterprise dokumentumkezelés egyik legidőigényesebb feladata és problémája a strukturálatlan tartalmakból történő metaadat-kinyerés. Egy szkennelt számla, egy beérkező e-mail csatolmánya vagy egy archivált szerződés PDF-je önmagában nem hordoz olyan indexelhető, kereshető információt, amit a dokumentumkezelő rendszer (DMS) hasznosítani tudna. Az AutoMeta erre a rétegre fókuszál: automatizált tartalom-transzformáció és metaadat-extrakció egy moduláris, JVM-alapú keretrendszerben.
A probléma és a megközelítés
A hagyományos dokumentumfeldolgozási láncokban az OCR szöveget állít elő, de a további lépések – nyelvfelismerés, típusbesorolás, mezőszintű adatkinyerés, célrendszerbe történő visszakerülés – általában egyedi scriptekből és manuális beavatkozásból állnak. Az AutoMeta ezt a folyamatot konfigurációalapú transzformációs láncokkal helyettesíti, ahol számtalan beépített lépés (transzformáció) kombinálható egymással: OCR, képminőség-javítás, vonalkód-felismerés, MRZ-olvasás, Machine Learning alapú klasszifikáció, LLM-integráció, JSON schema validáció, DOM manipuláció és mások.
A rendszer nem egy monolit alkalmazás, hanem réteges architektúrát követ: adatforrás-adapterek, központi feldolgozási motor (AutoMeta Core) és céladapterek. Ez lehetővé teszi, hogy bármilyen forrásból (CMIS repository, fájlrendszer, RDBMS, IMAP e-mail, WebDAV) bármilyen célba történjen migráció vagy helyben feldolgozás, metaadat-konverzióval.
Architektúra
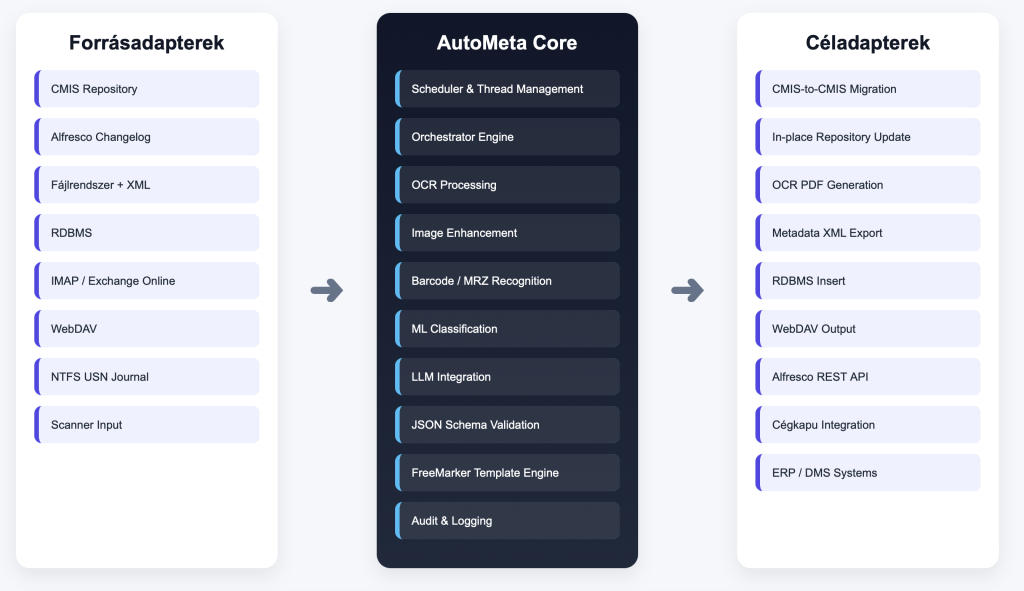
Az AutoMeta három fő rétegből áll:
Forrásadapterek: CMIS Atom és Browser binding (1.1 specifikáció), Alfresco changelog figyelő, fájlrendszer XML-metaadattal, RDBMS kapcsolat, WebDAV, IMAP/Exchange Online e-mail adapter, valamint NTFS USN Journal támogatás valós idejű változásfigyeléshez.
AutoMeta Core: Az ütemezés (scheduler) és szálkezelés biztosítja a párhuzamos feldolgozást. Az orchestrator a konfigurációban definiált transzformációs láncot hajtja végre dokumentumonként. A FreeMarker alapú template engine dinamikus metaadat-struktúrák generálására szolgál, az auditor pedig minden műveletet naplóz audit-célból.
Céladapterek: CMIS-to-CMIS migráció ID-megőrzéssel, in-place feldolgozás (azonos repository-ban), fájlrendszer XML-kimentés, RDBMS beszúrás, WebDAV, Alfresco REST API specifikus műveletek, valamint Cégkapu adapter az állami tárhelyekhez.
Feldolgozási módok
A rendszer két alapvető üzemmódban működik:
- Repository Crawler: Az AutoMeta aktívan csatlakozik a konfigurált forrásrendszerekhez, ütemezett ciklusokban lekéri a feldolgozandó dokumentumokat (pl. dedikált metaadattal jelölt iratok CMIS query-vel), feldolgozza azokat, majd visszakerüli az eredményt.
- Szerviz/Szolgáltatás mód: A tárolórendszer SOAP vagy REST hívással szólítja meg az AutoMeta-t, amikor új dokumentum érkezik. Ez a modell valós idejű feldolgozáshoz alkalmas, például szkennerről WebDAV-on keresztül érkező dokumentumok azonnali OCR-ezéséhez és indexeléséhez.
Adatkinyerés: fix és dinamikus mezők
A rendszer két típusú metaadat-kinyerést támogat:
A fix mezők előre definiált kulcs-érték párok, amelyek ismert struktúrából kerülnek kinyerésre – például számlaszám, teljesítés dátuma, végösszeg. Ezeket SAP integrációhoz XML tag-ekbe, vagy Alfresco aspectekbe (DublinCore, Summarizable, Effectivity) lehet betárolni.
A dinamikus mezők az Amazon Textract megközelítéséhez hasonlóan a dokumentum szövegében szereplő kulcsszavakból és azok kontextusából állítanak elő kulcs-érték párokat. Ez akkor hasznos, amikor a dokumentumok struktúrája változó, de az ismétlődő mintázatok felismerhetők.
Integráció Alfresco-val
Az Alfresco integráció CMIS protokollon keresztül valósul meg. A feldolgozandó dokumentumokat egy dedikált metaadattal (AutoMeta:status=0) kell jelölni, majd a rendszer több szálon dolgozza fel őket. Az eredményként kapott metaadatok és a transzformált bináris tartalom (pl. OCR-rel ellátott két rétegű PDF) új verzióként kerülnek vissza a repository-ba. A folyamat végén a dokumentum beltartalomra és metaadatra is kereshetővé válik.
A rendszer képes Alfresco-Alfresco replikációra is, Disaster Recovery site-ok közötti szinkronizálásra, valamint más DMS-ekből (SharePoint, FileNet, Nextcloud) történő időzített migrációra.
Tanítás és klasszifikáció
Az ML alapú klasszifikációs modul nyelvenként és dokumentumtípusonként tanítható. A tanítási felület csoportmunkát támogat többkörös ellenőrzéssel („négy szem elv”). Az AI elő-klasszifikációt végez, az emberi operátor pedig a javasolt értékeket ellenőrzi és szükség esetén korrigálja – ez az iteráció javítja a modell pontosságát. Globális minták is alkalmazhatók, amelyeket az integráció során az ügyfél dokumentumaihoz optimalizálnak.
Technikai megfontolások
Az AutoMeta egy JVM-ben fut, így platform-független és skálázható. Az on-premise működés garantálja, hogy az érzékeny adatok ne hagyják el a szervezet hálózatát, de cloud üzemeltetés is lehetséges. A konfiguráció XML alapú, ami szerkeszthető és verziózható, ugyanakkor a tanulási folyamat során a modellparaméterek finomhangolása komoly szakmai ismeretet igényel.
A rendszer egyértelmű erőssége a transzformációs láncok rugalmassága: egy feldolgozási pipeline tartalmazhat előfeldolgozást (képkorrekció, forgatás), OCR-t, ML klasszifikációt, LLM alapú szövegelemzést, JSON validációt és több célszerverre történő kimenetet – mindezt egyetlen konfigurációban.
Összefoglalva az AutoMeta egy dokumentumfeldolgozási middleware, amely a strukturálatlan tartalmak és a vállalati DMS/ERP rendszerek közötti réteget tölti ki. Nem helyettesíti a dokumentumkezelő rendszert, hanem annak feldolgozási képességeit bővíti automatizált metaadat-kinyeréssel, formátumkonverzióval és tárolók közötti migrációval. A collAIgue appliance szintén az AutoMeta komponenseire épül, annak keretrendszerét használva kommunikációra és auditálásra.
